I. Introduction
This is a short post about making a Hidden Markov Model (HMM) in Scala using Figaro. We’ll see how to code up our own HMM and do inference on an it. Along the way, we’ll see how functional programming fits naturally into programming with probability distributions. All of the code is here so have at it.
II. Our HMM
An HMM is a probabilistic graphical model that looks like this

It has finite sets of hidden and observable states, each node 
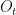

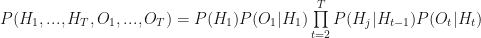
So everything depends on the a priori distribution 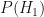
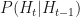
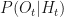

Our example will be the one from wikipedia: our friend Bob does one of three things, go shopping, go for a walk, or clean his house, depending on the weather which can be either rainy or sunny. We cannot observe the weather where Bob is, we just talk to him on the phone, hear what he has done on various days, and try to infer the weather or what he did on other days.
So our states are
sealed trait Hidden case object Rainy extends Hidden case object Sunny extends Hidden sealed trait Observable case object Shop extends Observable case object Clean extends Observable case object Walk extends Observable
We’ll use the convention that vectors are row vectors and multiply matrices from the left; this is consistent with pattern matching syntax as we’ll see. So, our transition matrix is 2 x 2, our emission matrix is 2 x 3, and both are row stochastic, that is, the rows are probability distributions (numbers between 0 and 1 that add up to 1). Abbreviating 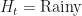
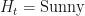
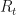
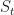
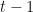
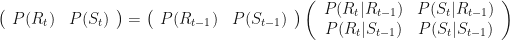
The left-hand side is a vector, the distribution over states at time t, the right-hand side a vector times a matrix, the distribution over states at time t-1 times the transition matrix. The definition and mechanics of the emission matrix are completely analogous.
Let’s take a moment to bask in the warm glow of being able to make our own union types: rather than using Integers, say, to model our states and then having to remember which Integer corresponds to which state, we can just say what we mean.
We’ll see how to build our HMM, but first let’s make a short digression on programming with probability distributions.
III. Probabilistic Functional Programming
Morally, a probability distribution of type A is a list of pairs
type Dist[A] = List[(A, Double)]
consisting of each of the values of A along with the probability of drawing that value when you sample from the distribution. So the Doubles should all be between 0 and 1 and sum to 1.
If you sample from the same distribution multiple times, you don’t necessarily get the same answer every time so Here Be Non-determinism which, to a functional programmer, says monad: non-determinism is icky and we had better protect our pure code from it at all cost (by putting it inside a monad). Dist[_] also clearly, and less ickily, says functor so let’s start there.
For Dist[_] to be a functor, we have to say how, given a function A => B, we make a function Dist[A] => Dist[B]. Here’s what we do: if we have a List[(A,Double)], and a function f : A => B, we first apply f to the first component of every tuple to get a List[(B,Double)], then, if f maps multiple values of type A to the same value of type B, we combine tuples with the same first component by adding the probabilities. (In SQL, this is just a sum…group by…)
Beyond our visceral reaction to non-determinism, it’s reasonable that Dist[_] should be a monad because List[_] is a monad and Dist[_] is a list. Moreover, it’s a list of tuples of things whose second components we know how to add and multiply: we should be able to figure out some clever way to flatten a list of tuples of lists of tuples of such things into a list of tuples of such things. So, given a Dist[A] and a function A => Dist[B], we need to make a Dist[B]. Let’s do an example to see how. Suppose we have a function Hidden => Dist[Hidden]
def transitionGivenState(h : Hidden) : Dist[Hidden] = {
h match {
case Rainy => List((Rainy, 0.7), (Sunny, 0.3)) // List(P(R_t | R_{t-1}), P(S_t | R_{t-1})
case Sunny => List((Rainy, 0.2), (Sunny, 0.8)) // List(P(R_t | S_{t-1}), P(S_t | S_{t-1}))
}
}
which gives us the distribution over (hidden) states at time t given the state at time t-1. But, we don’t know the actual state at time t-1, we again have just a distribution
val d : Dist[Hidden] = List((Rainy, 0.1), (Sunny, 0.9)) // List(P(R_{t-1}), P(S_{t-1}))
We know how to do this because it is exactly our transition matrix example: monadic bind (flatMap) is matrix multiplication! In Scalamatical pseudocode meant to suggest vectors and matrices, we have:
d flatMap transitionGivenState = Rainy => List((Rainy, 0.7), (Sunny, 0.3)) List((Rainy, 0.1), (Sunny, 0.9)) fM Sunny => List((Rainy, 0.2), (Sunny, 0.8)) = List((Rainy, 0.1 * 0.7 + 0.9 * 0.2), (Sunny, 0.1 * 0.3 + 0.9 * 0.8)) = List((Rainy, 0.25), (Sunny, 0.75))
(There is no SQL analogue of this, but in Hive, we can do it with a lateral view explode.)
The punchline is that matrix multiplication is all we need to define a probability distribution as a monad. It’s pretty fantastic that monadic bind is exactly the thing to model dependencies between probability distributions. That is some deep math at work. This is what Wadler means when he says that FP is discovered, not invented.
IV. An HMM in Figaro
The Figaro type for modeling a probability distribution is called Element[_]. It does more internal book-keeping than our simple type Dist[_], but it’s the same idea: a set of values and a probability for each. The Figaro way of writing
val d : Dist[Hidden] = List((Rainy, 0.1), (Sunny, 0.9))
is
val fd : Element[Hidden] = Select(0.1 -> Rainy, 0.9 -> Sunny)
Element is both a functor and a monad; in Figaro, map and flatMap are called Apply and Chain, but you can write each either way. Warning: Figaro is not a purely functional library, Elements are mutable as we’ll see in the next section. The Figaro machinery for sampling from distributions requires a little more from our types so we use
type H = Product with Serializable with Hidden type O = Product with Serializable with Observable
We can define a function that takes the conditional probabilities which define the transition matrix as input, and makes the corresponding function for us
def transition(rainyTransition : Array[Double], sunnyTransition : Array[Double])(e : Element[H]) : Element[H] = {
def transitionGivenState(h : H) : Element[H] = {
h match {
case Rainy => Select(rainyTransition(0) -> Rainy, rainyTransition(1) -> Sunny) // P(H | Rainy)
case Sunny => Select(sunnyTransition(0) -> Rainy, sunnyTransition(1) -> Sunny) // P(H | Sunny)
} // these are the rows of the 2x2 transition matrix
}
e.flatMap(transitionGivenState) // P(H) = P(H | Rainy) P(Rainy) + P(H | Sunny) P(Sunny)
}
exactly as we did in our example. Given the rows of the transition matrix, this produces a function of type Element[H] => Element[H]. We can define a similar function to make the emission matrix
def emission(rainyEmission : Array[Double], sunnyEmission : Array[Double])(e: Element[H]) : Element[O] = {
def emissionGivenState(h : H) : Element[O] = {
h match {
case Rainy => Select(rainyEmission(0) -> Shop, rainyEmission(1) -> Clean, rainyEmission(2) -> Walk) // P(O | Rainy)
case Sunny => Select(sunnyEmission(0) -> Shop, sunnyEmission(1) -> Clean, sunnyEmission(2) -> Walk) // P(O | Sunny)
} // these are the rows of the 2x3 emission matrix
}
e.flatMap(emissionGivenState) // P(O) = P(O | Rainy) P(Rainy) + P(O | Sunny) P(Sunny)
}
which, given the rows of the emission matrix, produces a function of type Element[H] => Element[O]. To make a sequence of hidden states in which each is obtained from the previous by applying the transition matrix we need an a priori distribution, a transition matrix, and the length.
def makeHiddenSequence(length : Int, transitionMatrix : Element[H] => Element[H], aprioriArray : Array[Double]) : List[Element[H]] = {
val apriori = Select(aprioriArray(0) -> Rainy, aprioriArray(1) -> Sunny) // the apriori distribution over hidden states
def buildSequence(n : Int, l: List[Element[H]]) : List[Element[H]] = {
(n, l) match {
case (0,l) => l // Step 3: when we get down to n = 0 we are done
case (n, Nil) => buildSequence(n-1, List(apriori)) // Step 1: start with the apriori distribution
case (n, x :: xs) => buildSequence(n-1, transitionMatrix(x) :: x :: xs) // Step 2: apply the transitionMatrix to the head and cons it onto the list
}
}
// reverse so time increases from left to right.
buildSequence(length, Nil).reverse
}
Finally, to make the corresponding sequence of observable states, we just apply the emission matrix to each hidden state.
def makeObservableSequence(hiddenSequence : List[Element[H]], emissionMatrix : Element[H] => Element[O]) : List[Element[O]] = {
hiddenSequence.map(emissionMatrix)
}
We can put this all together into a class and make a companion object that lets us make an HMM with given or default parameters.
class HMM(
val length : Int
, val apriori : Array[Double]
, val rainyT : Array[Double]
, val sunnyT : Array[Double]
, val rainyE : Array[Double]
, val sunnyE : Array[Double]
) {
val hidden : List[Element[H]] = makeHiddenSequence(length, transition(rainyT, sunnyT), apriori)
val observable : List[Element[O]] = makeObservableSequence(hidden, emission(rainyE, sunnyE))
}
object HMM {
val apriori = Array(0.4, 0.6)
val rainyT = Array(0.6, 0.4)
val sunnyT = Array(0.3, 0.7)
val rainyE = Array(0.2, 0.7, 0.1)
val sunnyE = Array(0.4, 0.1, 0.5)
def apply(length : Int) : HMM = new HMM(length, apriori, rainyT, sunnyT, rainyE, sunnyE)
def apply(
length: Int
, apriori : Array[Double]
, rainyT : Array[Double]
, sunnyT : Array[Double]
, rainyE : Array[Double]
, sunnyE : Array[Double]
) : HMM = new HMM(length, apriori, rainyT, sunnyT, rainyE, sunnyE)
}
V. Inference
Now that we’ve set everything up, we can use Figaro’s machinery for inference. The examples in this section are here.
First, we can do belief propagation: we can query our HMM to ask the probability that it was Sunny on day 2, say, and, if we learn that Bob took Walks on other days, we can use that evidence to update our belief. We do this with Figaro’s VariableElimination. See Bishop chapters 8 and 13 and/or Koller and Friedman chapter 9 for great discussions of Variable Elimination and the sum-product algorithm.
scala> VEexample() Probability it is Sunny on day 2 Prior probability: 0.574 After observing Walk on day 2: 0.870752427184466 After observing Walk on day 1: 0.9073645970937912 After observing Walk on day 0: 0.9112495643081212 After observing Walk on day 3: 0.9375250668843456 After observing Walk on day 4: 0.9404138925801485 After observing Walk on day 5: 0.9407314643168659
As we see, the probability that it was Sunny on day 2 increases as we observe that Bob went for walks on various days, even on days later in the week. As warned, Elements are mutable. We incorporate new evidence with hmm.observable(2).observe(Walk), for example, which collapses the distribution on day 2 to the one with probability 1 of observing Walk and 0 of observing any other activity. We can always unobserve, though, so not all is lost.
Next, given a sequence of observations Clean, Shop, Clean, Walk, say, we can ask what the weather most likely was on those days. This can mean one of two things: either we find the sequence of hidden states which maximizes the probabilities individually, so maximizes 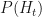

mostLikelyHiddenStates and the second mostLikelyHiddenSequence.
To compute the mostLikelyHiddenStates, we just use VariableElimination again: we apply it for each t individually and choose the state with the highest probability.
To compute the mostLikelyHiddenSequence, we use Figaro’s Most Probable Explanation (MPE). In the literature, this is called the max-sum algorithm for tree-like PGMs or the Viterbi algorithm for HMMs. See the same references.
We have functions that do each and the function mostLikelyExample() compares the two
scala> mostLikelyExample() For the observation sequence: List(Clean, Shop, Clean, Walk) The most likely hidden states are: List(Rainy, Sunny, Rainy, Sunny) which has probability 0.19539752430007473 The most likely hidden sequence is: List(Rainy, Rainy, Rainy, Sunny) which has probability 0.2930962864501122
This example comes from the Stamp tutorial where he works it out in detail so see there for careful calculations and discussion. See the code comments in mostLikelyExample() for the mapping between our states and Stamp’s.
So, we can do belief propagation, and, given an observation sequence, we can find the most likely corresponding hidden states two ways. What about inferring the parameters of the model from data? Parameter learning comes in two flavors: supervised and unsupervised.
In the supervised case, our training dataset would consist of a collection of observation sequences and the corresponding sequences of hidden states. We can just compute the parameters of the model by doing frequency counts: the probability that a given state follows another is just the fraction of times that happens in the training set. This is similar to a Naive Bayes classifier.
In the unsupervised case, our training set would consist just of a collection of observation sequences and we would use the Expectation Maximization algorithm to learn the coefficients of the a priori distribution and transition and emission matrices. Figaro implements EM, but using it requires changing some types to make them compatible with parameter learning. Hopefully, this will be the topic of a future post.
Conclusion
This is not blazingly original work, it just comes from reading the excellent Figaro book and following ideas up in Bishop and other references. Nonetheless, I hope this has been a fun tour through the Math-Machine Learning-Functional Programming 2-simplex and that having code to play with brings the ideas home.
References
Figaro
- Practical Probabilistic Programming MEAP by Avi Pfeffer
- Figaro on Github
HMMs and beyond
- A Revealing Introduction to Hidden Markov Models (pdf) by Stamp
- An Introduction to Hidden Markov Models and Bayesian Networks (pdf) by Gharamani
- A Tutorial on Hidden Markov Models with Selected Applications to Speech Recognition (pdf) by Rabiner
- Pattern Recognition and Machine Learning (book) by Bishop. In particular, chapter 8 on probabilistic graphical models and chapter 13 on HMMs.
- Probabilistic Graphical Models: Principles and Techniques (book) by Koller and Friedman.
- Probabilistic Graphical Models (videos), Koller’s Coursera class.
Probabilistic Functional Programming
- Probabilistic Functional Programming in Haskell (pdf) by Erwig and Kollmansberger
- Practical Probabilistic Programming with Monads (pdf) by Scibior, Ghahramani, and Gordon
- Scala for Machine Learning (book, has a chapter on HMMs)

